N+1 data fetching is a notorious problem in software world in general but more so prominent in GraphQL world. In this post, we will visually unpack what N+1 data fetching means, why it's problematic and how to solve for it.
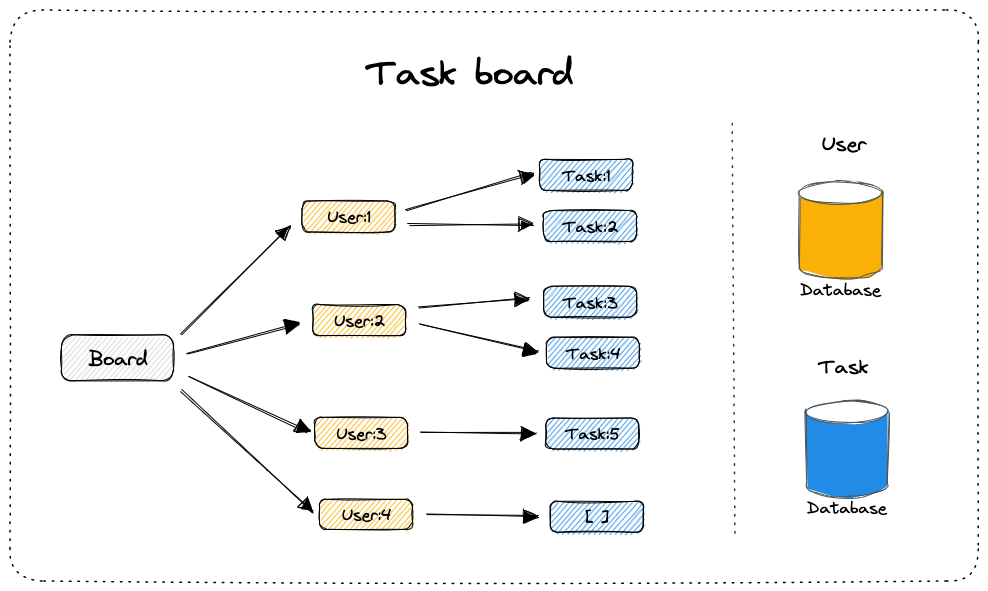
Let's take a task board as an example.
- A board has 0-to-many number of users
- Each user has 0-to-many number of tasks associated to them
To fully display a board, we need to fetch the user and task information for the board.
Fetching relational data
There are two common ways to fetch related entities, i.e to fetch users and tasks for the current board.
N+1 data fetching
We first fetch all the users for the current board in one request. Then we iterate through the user response and fetch the tasks for each user (in parallel of course) in separate requests.
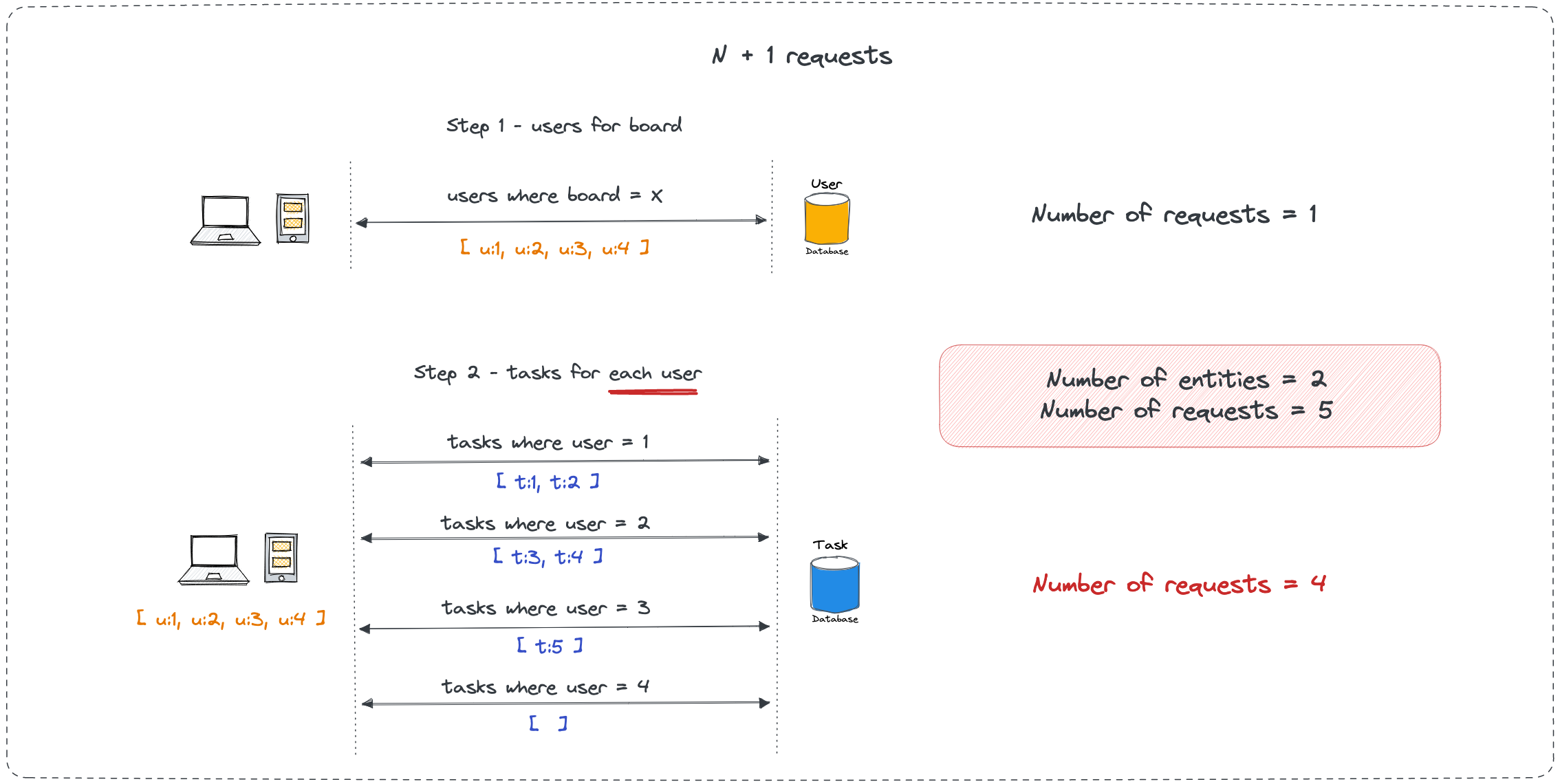
Current board has about 4 users with each user having a few tasks of their own. To get all the necessary data, we end up sending 4 + 1 requests, one to get all the users and then one for each user's tasks. We have sent N+1 requests. If we had 200 users on the board, we'd have ended up sending 201 requests to get all the tasks.
This is what is commonly referred to as N+1 request waterfall. We sent 5 requests to fetch the data for two entities (users and tasks). This creates more work for the server/database than necessary. It's better to get all the results of one entity (tasks) in one request than through many requests, even if they are sent in parallel.
It's always better to get 100 results of a single entity in one request than in 100 requests.
1+1 data fetching
We first fetch all the users for the current board in one request. Then we iterate through the response, collect all the user ids and fetch all the tasks for the collected user ids in a single request.
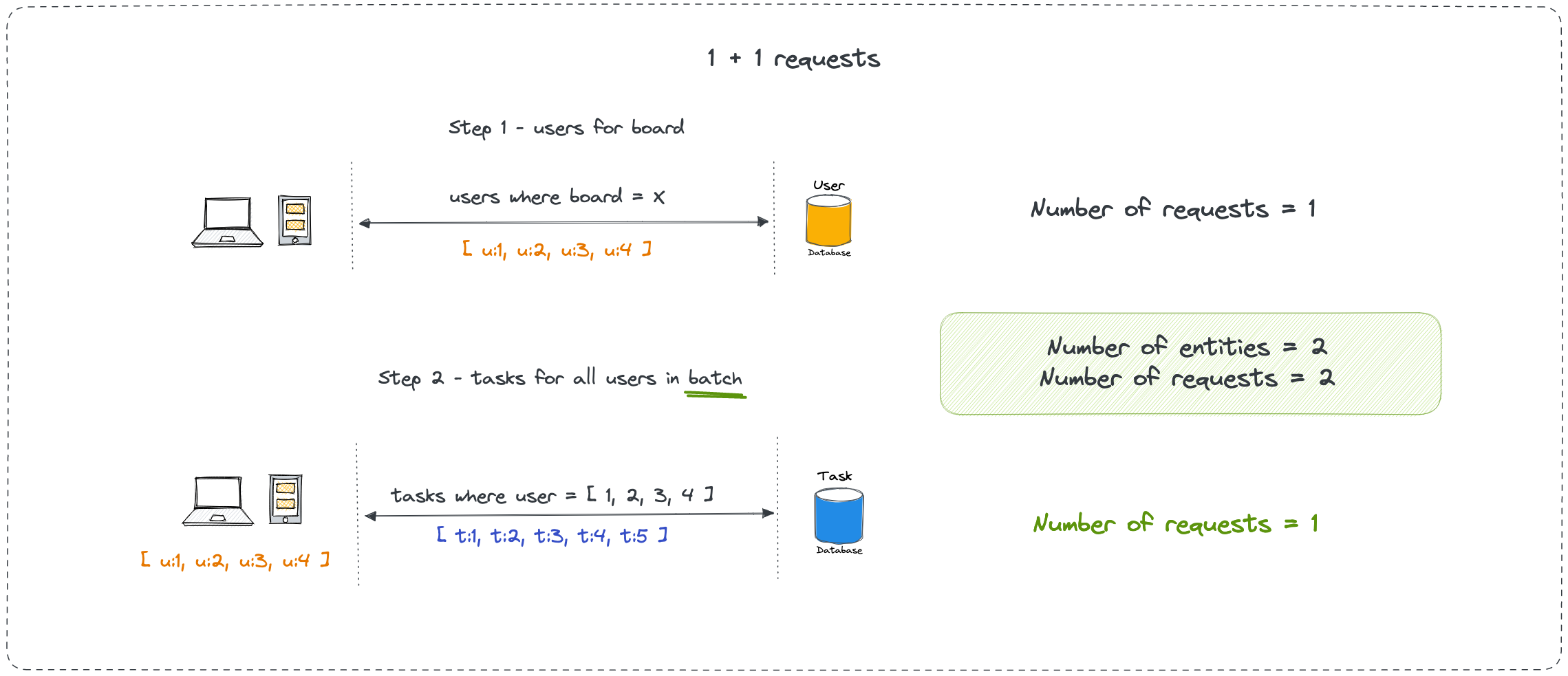
We sent 2 requests to fetch the data for two different entities (users and tasks). This is the preferred way to fetch related data.
If you need data from 10 different entities, you should send no more than 10 requests to get the data you need.
Solving the N+1 problem in REST
Solving the N+1 problem in REST APIs is mostly straight forward. In REST world, every endpoint is tailored for a particular feature or a data model. If you ever find yourself sending N+1 requests from a REST endpoint, just rewrite your code to collect the arguments and batch them all in a single request.
// N+1 requests
router.get("/users-with-tasks", async function (request, response) {
const users = await userDB.findAll(request.query.boardId);
const usersWithTasks = await Promise.all(
users.map(async (user) => {
// 1 request for each user
const tasksForUser = await taskDB.findByUserId(user.id);
return {
...user,
tasks: tasksForUser,
};
}),
);
return usersWithTasks;
});
// 1+1 requests
router.get("/users-with-tasks", async function (request, response) {
const users = await userDB.findAll(request.query.boardId);
const userIds = users.map((user) => user.id);
// 1 request for all users
const tasks = await taskDB.findByUserIds(userIds);
const usersWithTasks = users.map((user) => {
const tasksForUser = tasks.filter((task) => task.userId === user.id);
return {
...user,
tasks: tasksForUser,
};
});
return usersWithTasks;
});
Solving the N+1 problem in GraphQL
In GraphQL, you don't build types tailored for a feature or a data model, instead you build your data graph. N+1 problem is more prominent in GraphQL world because of the way the resolvers are spec'ed to work. Resolvers are invoked hierarchically per type which is often referred to as resolver chaining. In our example, first the resolver for Query.users would be invoked, then the resolver for each user.tasks would invoked. Resolvers don't know if the parent type is a single object or a list of objects. That's why type resolvers are invoked for every single user to fetch tasks per user.
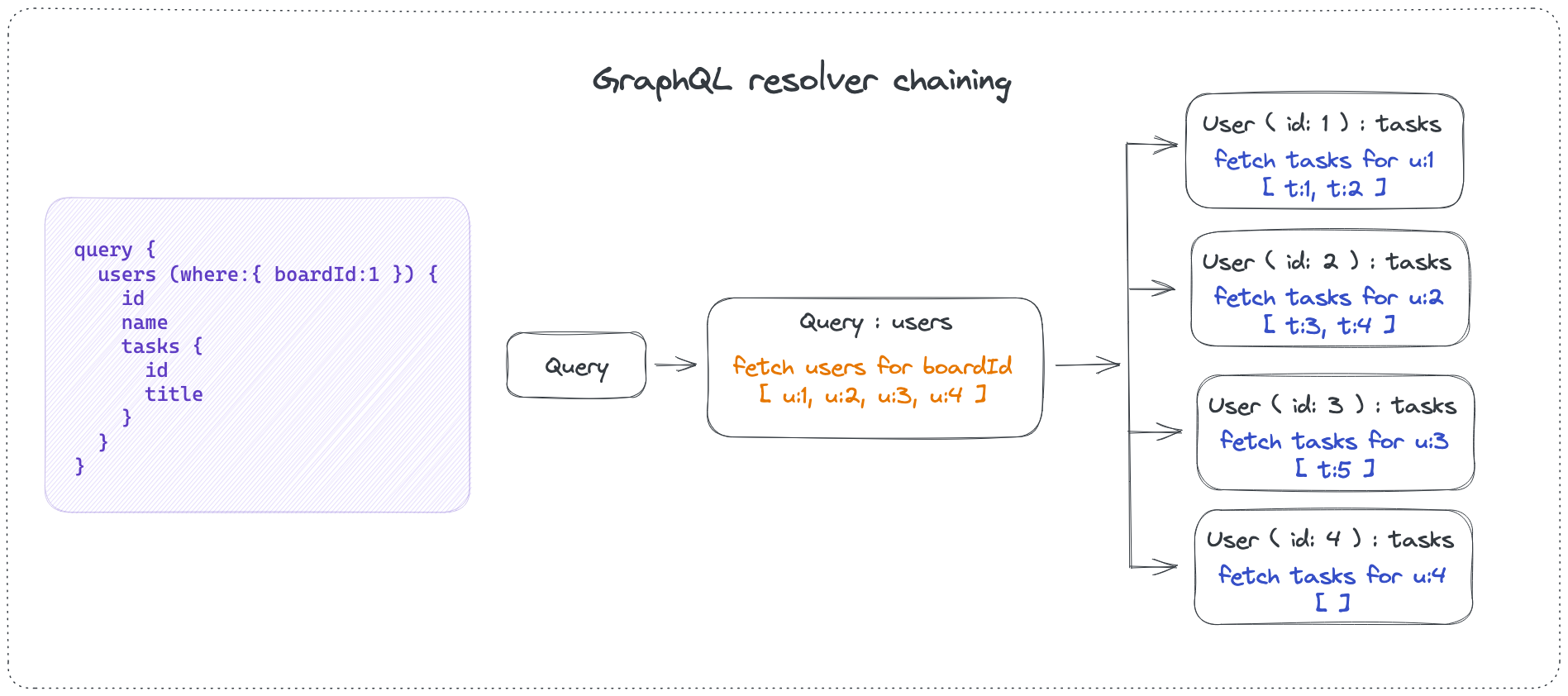
IMO resolvers not knowing if the parent type is a list and not being able to access the entire list of the parent type is a serious limitation of the spec. Resolvers should be able to access the entire list of parent type if needed.
So to be able to get the list of parent type's id (all users id) in resolvers before sending the network/database request, a common pattern is to batch the promises in resolvers and flush them all at once using process.nextTick() (for non-node environments setImmediate() is the closest alternative). dataloader a popular npm package to help with N+1 problem for GraphQL servers written in JavaScript.
Dataloader is maintained by the wonderful folks at Meta's Relay team. It solves the problem but I've often found it to fall short for my abstractions. Dataloader achieves two distinct purposes via the same API - batch requests and cache requests. To initialize the request cache, dataloaders need to be initialized per request usually in GraphQL context object. I like to have my caching concerns separate from my batching concerns. So I have published an npm package that does just the request batching without having to be setup in GraphQL context object. Check it out here: next-batch. Both these packages achieve request batching the same way (using process.nextTick()) with slightly different APIs. You can't go wrong with either.
Here's a visual representation of how process.nextTick() collects the promises in the resolvers and the sends the network/database request when the queue is flushed. The representation is not entirely accurate around the call stack area since users will be popped out of the stack as soon as they are resolved, but I left it there for better visual interpretation of the our example.
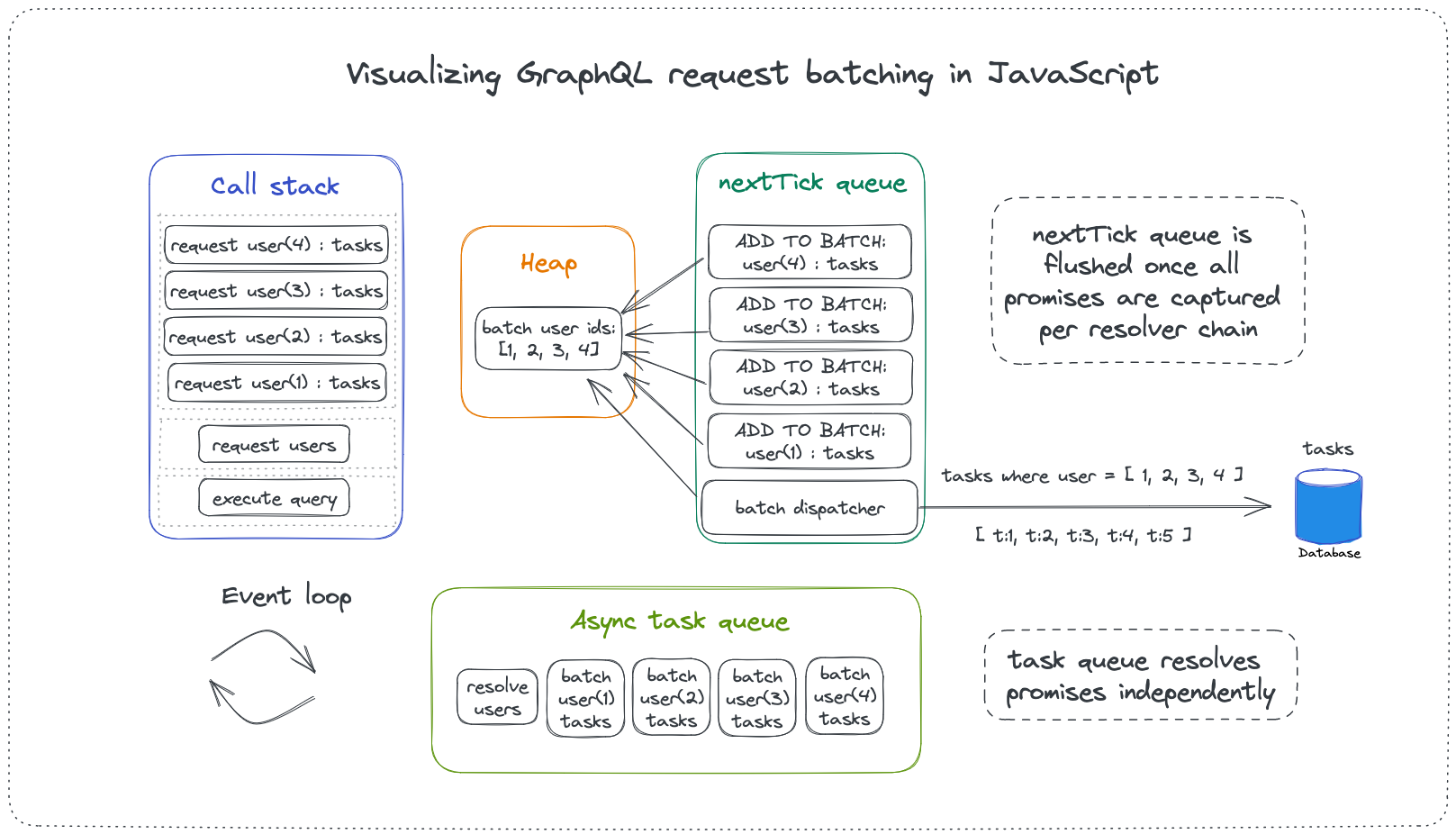
All the requests from the resolvers of the same type (User.tasks) are queued in a single frame of execution in the event loop. The batch utility captures these requests, batches them together and schedules the batch to be flushed in the next tick of the event loop. When the batch is flushed, a single network/database request is sent for the data. And that, my friends, is how we solve for the N+1 data fetching problem in GraphQL servers written in JavaScript.
Recap
- N+1 data fetching means you are sending more requests than necessary to fetch the data you need.
- It is easy to avoid N+1 data fetching in REST APIs.
- It is not easy to avoid N+1 data fetching in GraphQL because of the way resolvers are designed to work.
- I have published an npm package to help solve the N+1 problem in GraphQL resolvers with a simple, no-setup-needed API.
If you have thoughts or questions, hit me up in Twitter @flexdinesh.